Handwritten Digits OCR
Handwritten digits have wide applications. SSNs, credit card numbers, telephone numbers are commonly seen in written forms. Digitizing these data is an important task for archiving, encryption and transferring purposes. A naive approach for these task is to recognize the texts by human eyes and typing the data into the computer. This approach, though viable, is not scalable. This is when Computer Vision techniques can be applied. One of the earliest application of computer vision involves pioneering work from Yann Lecun to recognize written postcodes in sorting facilities of US postal service.
This project explores two different but interally correlated tasks of digits note: note region scanning and digit recognition. For note region scanning, this application recognizes the borders of a written note from any photo, then aligns them to the 4 corners of the image. An extracted note region is aligned and any handwritten texts (assuming left to right) on the note has a horizontal layout. It can then be sent to the second stage for digit recognition. The output of the application includes an extracted image of the note and txt format of digits written on the note.
Note Region Scanning
Commonly speaking, a note region is rectangular. In order to highlight the rectangular region, most importantly, to distinguish the borders of the note from the rest of the image, we preprocess the input photo with Canny transform, which outputs an image that binearize the egdes in the photo. We further cleaned the transformed-image with non-maximal suppression in 8 directions for each pixel. The transformed is a binearized photo, where apparent edges is marked as 1, the rest is marked as 0.

Canny Transformed
With Canny transformed image, we will then apply Hough transform to convert the image from x-y coordinate space to rho-theta space. Any line that appears in x-y space will show up as a dot in rho-theta space. Statistically we have more tools to deal with dots then lines - namely, data clustter. We then apply k-means clusttering to find the top-4 clusters from the rho-theta space. The result could be converted for the edges of the rectangular region in the input photo. Computing the intersects of the edges results in the 4 corners of the region.

Hough Space - the 4 dense points represent the 4 detected edges
After locating the corners we used a technique commonly used in panorama stiching - projection transform, to warp the region to 4 corners. Eigen library was used to assist solving matrix equations.
Digits Recognition
Challenges
The output from above mentioned procedure generates an “aligned” noted from given photo. Still, recognizing the texts within poses a great challenge. The orientation of the texts is unknown: for Germanic and Romanic, as well as some East-Asian texts, writing horizontally from left to right is common. While for Japonic and Arabic languages, writing from right to left, top to bottom is more common.
Besides orientation, there exists large variations in text and line space. Printed texts are usually easier to recognize since they tends to have fixed width (for monospace fonts), and fixed height for lines. For written texts, line width and heights varies, text width and heights also varies. In some written texts there may be no spaces between characters.
Finally, written texts have fonts largely related to the writer’s personaly writing habit. Some handwritten texts have artistic stlyes, which could have vastly different looks to a different text, while meaning the same thing. The recognizer should take these factors into consideration.
This application takes on a simpler pre-condition, where digits are written from left to right, and the digits are spaced out from each other. We first use contour extraction to detect the digits and use a convolutional neural network (CNN) to recoginize them.

Various texts forms - printed, and written calligraphy arts
Text Detection
The goal for text detection is to generate a bounding box for each characters of the text. The quality of the bounding box relates to the ultimate quality of the recognizer. (Even the best digit recognizer cannot infer “8” if only its upper half was detected) In general, two different detecting techniques were used - statistical and contour. Though both were implemented in the projects, contour based method is better suited for free-formed objects in application. Contour methods identifies the largest rectangular region each character cover from its own pixel sets, it is rather robust to variations of strokes for each character, yet prone to texts with connected strokes between characters.
When the bounding boxes are generated, there should be a sorting process to determine the order. We designed a scanline approach with inspiration from the statistical approach in bounding box detection. We first group the bounding boxes by lines, then order them according to there relative pixel position.
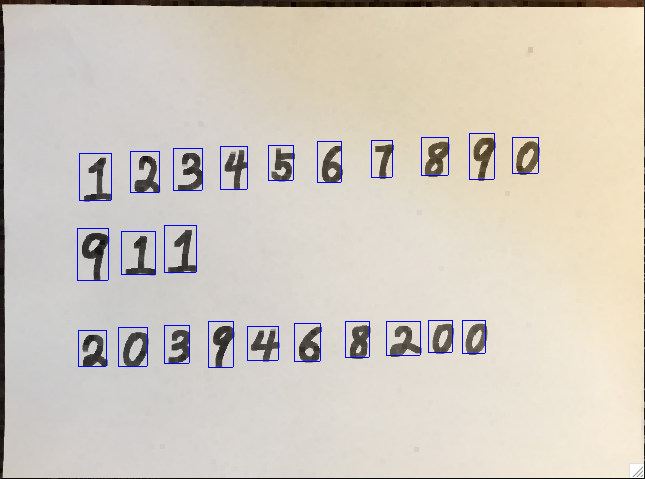
Bounding boxes detected for each characters
Text Recognition
In order to cope with varied scenarios of hand-written digits, a learning based approach is commonly used. Learnt models, such as support vector machine (SVM) or convolutional neural network (CNN) contains large set of parameters learnt from a large handwritten datasets. Each part of the learnt model accounts for some features of the handwritten character, such as width of strokes, inclinations, loops etc. A hierachical architecture such as CNN consists of several layers, the higher the layer the more abstract features a model learns.
In this application, we trained a neural network inspired from top-ranking Kaggle architecture using MNIST dataset. The model weights was saved and were loaded to the application on the fly. We then feed the raw pixels of the extracted region into the neural net according to the orders determined above. The prediction of the network is then recorded as a text file and written on the original image.
Future Improvements
For note region extraction, current algorithm is prone to varied lighting conditions. For example, if some specular light lies between the border of the note and its background, Hough transform may fail to detect the border since the edge is blurred. Varied lighting conditions also affects text detection. A strong shadow casted upon a character could make it too dark to appear in the binearized image. In these scenarios, a global image light balancing preprocess stage.
Another approach is to apply learnt models to both text detection and border extraction. A learning based model is robust under various conditions, including different lighting scenarios, orientations and occlusions. For text detection, it can handle connected characters and different writing styles, as long as the dataset contains such images. Such system is end to end, reducing cumulated error from a multi staged system.

Cumulated error could lead to wrong recognitions.