Fairseq Transformer, BART
BART is a novel denoising autoencoder that achieved excellent result on Summarization. It is proposed by FAIR and a great implementation is included in its production grade seq2seq framework: fariseq. In this tutorial I will walk through the building blocks of how a BART model is constructed.
Transformer Model
BART follows the recenly successful Transformer Model framework but with some twists. So let’s first look at how a Transformer model is constructed.
Overview
Fairseq adopts a highly object oriented design guidance. At the very top level there is
a Transformer class that inherits from a FairseqEncoderDecoderModel, which in turn inherits
from a BaseFairseqModel, which inherits from nn.Module. These are relatively light parent
classes and many methods in base classes are overriden by child classes. We will focus
on the Transformer class and the FairseqEncoderDecoderModel.
Besides, a Transformer model is dependent on a TransformerEncoder and a TransformerDecoder
module. A TransformerEncoder requires a special TransformerEncoderLayer module. The
TransformerEncoder module provids feed forward method that passes the data from input
to encoder output, while each TransformerEncoderLayer builds a non-trivial and reusable
part of the encoder layer - the layer including a MultiheadAttention module, and LayerNorm.
Similarly, a TransforemerDecoder requires a TransformerDecoderLayer module. Specially,
a TransformerDecoder inherits from a FairseqIncrementalDecoder class that defines
incremental output production interfaces. Finally, the MultiheadAttention class inherits
from FairseqIncrementalState, which allows the module to save outputs from previous timesteps.
To sum up, I have provided a diagram of dependency and inheritance of the aforementioned modules as below. Note that dependency means the modules holds 1 or more instance of the dependent module, denoted by square arrow. And inheritance means the module holds all methods and attributes from parent class, denoted by angle arrow.
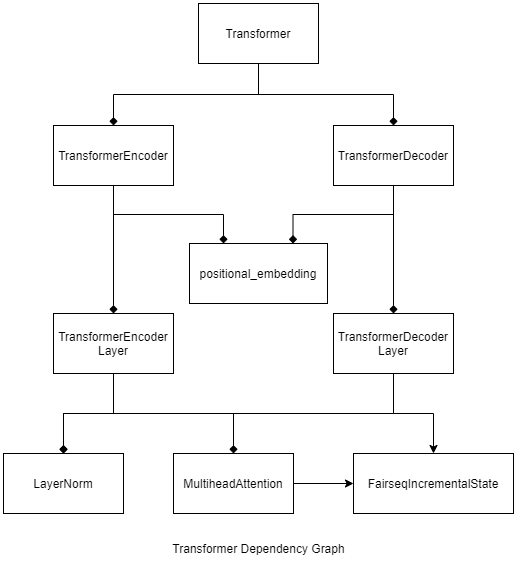
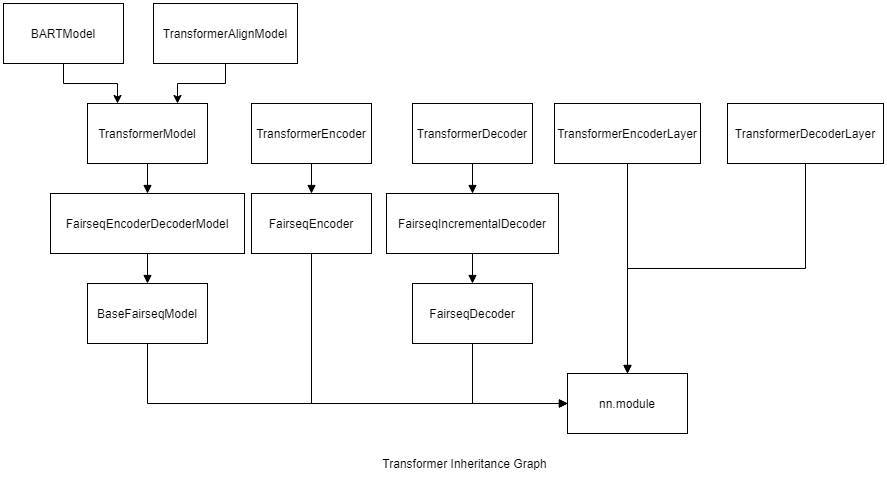
TransformerModel
A TransformerModel has the following methods, see comments for explanation of the use
for each method:
@register_model("transformer")
class TransformerModel(FairseqEncoderDecoderModel):
# defines where to retrive pretrained model from torch hub
@classmethod
def hub_models(cls):...
# pass in arguments from command line, initialize encoder and decoder
def __init__(self, args, encoder, decoder):...
# adds argument to command line entrance
@classmethod
def add_args(parser):...
# compute encoding for input, construct encoder and decoder, returns a
# Transformer instance
@classmethod
def bulid_model(cls, args, task):...
# helper function to build an encoder
@classmethod
def build_encoder(cls, args, src_dict, embed_tokens):...
# helper function to build a decoder
@classmethod
def build_decoder(cls, args, tgt_dict, embed_tokens):...
# mostly the same with FairseqEncoderDecoderModel::forward, connects
# encoder and decoder.
def forward(
self, src_tokens, src_lengths, prv_output_tokens,
cls_input, return_all_hiddens, features_only,
alingment_layer, alignement_heads
):...
This is a standard Fairseq style to build a new model. By using the decorator
@register_model, the model name gets saved to MODEL_REGISTRY (see model/
__init__.py), which is a global dictionary that maps the string of the class
name to an instance of the class.
Another important side of the model is a named architecture, a model maybe
bound to different architecture, where each architecture may be suited for a
specific variation of the model. Along with Transformer model we have these
architectures:
@register_model_architecture("transformer", "transformer")
def base_architecture(args):...
@register_model_architecture("transformer", "transformer_iwslt_de_en")
def transformer_iwslt_de_en(args):...
@register_model_architecture("transformer", "transformer_wmt_en_de")
def transformer_wmt_en_de(args):...
# parameters used in the "Attention Is All You Need" paper (Vaswani et al., 2017)
@register_model_architecture("transformer", "transformer_vaswani_wmt_en_de_big")
def transformer_vaswani_wmt_en_de_big(args):...
...
The architecture method mainly parses arguments or defines a set of default parameters
used in the original paper. It uses a decorator function @register_model_architecture,
which adds the architecture name to a global dictionary ARCH_MODEL_REGISTRY, which maps
the architecture to the correpsonding MODEL_REGISTRY entry. ARCH_MODEL_REGISTRY is
then exposed to option.py::add_model_args, which adds the keys of the dictionary
to command line choices. I suggest following through the official tutorial to get more
understanding about extending the Fairseq framework.
Two most important compoenent of Transfomer model is TransformerEncoder and
TransformerDecoder.
TransformerEncoder
A TransformerEncoder inherits from FairseqEncoder. FairseqEncoder is an nn.module.
FairseqEncoder defines the following methods:
# FairseqEncoder.py
EncoderOut = NamedTuple(
"EncoderOut",
[
("encoder_out", Tensor), # T x B x C
("encoder_padding_mask", Tensor), # B x T
("encoder_embedding", Tensor), # B x T x C
("encoder_states", Optional[List[Tensor]]), # List[T x B x C]
],
)
class FairseqEncoder(nn.Module):
# initialize the class, saves the token dictionray
def __init__(self, dictionary):...
# Required to be implemented
def forward(self, src_tokens, src_lengths=None, **kwargs):...
# The output of the encoder can be reordered according to the
# `new_order` vector. Requried to be implemented
def reorder_encoder_out(self, encoder_out, new_order):...
# An arbitrary large positive number
def max_positions(self):...
# For old Fairseq version compatibility
def upgrade_state_dict(self, state_dict):...
Besides, FairseqEncoder defines the format of an encoder output to be a EncoderOut
type. EncoderOut is a NamedTuple. The items in the tuples are:
encoder_out: of shapeTime x Batch x Channel, the output of the encoder.encoder_padding_mask: of shapeBatch x Time. It’s of the same length of each input, acting as the bitwise mask to show which part of the sentence is padding.encoder_embedding: of shapeTime x Batch x Channel, the word embeddings before applying the positional encoding, layer norm and dropout.encoder_states: of shapelist[Time x Batch x Channel], intermediate output from the encoder, may beNoneif not needed.
The Transformer class defines as follows:
class TransformerEncoder(FairseqEncoder):
# initialize all layers, modeuls needed in forward
# including TransformerEncoderlayer, LayerNorm,
# PositionalEmbedding etc.
# embed_tokens is an `Embedding` instance, which
# defines how to embed a token (word2vec, GloVE etc.)
def __init__(self, args, dictionary, embed_tokens):...
# forward embedding takes the raw token and pass through
# embedding layer, positional enbedding, layer norm and
# dropout
def forward_embedding(self, src_tokens):...
# Forward pass of a transformer encoder. Chains of
# TransformerEncoderLayer. Returns EncoderOut type.
def forward(
self,
src_tokens,
src_lengths,
cls_input: Optional[Tensor] = None,
return_all_hiddens: bool = False,
):...
def reorder_encoder_out(self, encoder_out: EncoderOut, new_order):...
def max_positions(self):...
In forward pass, the encoder takes the input and pass through forward_embedding,
then pass through several TransformerEncoderLayers, notice that LayerDrop[3] is
used to arbitrarily leave out some EncoderLayers.
TransformEncoderLayer
A TransformEncoderLayer is a nn.Module, which means it should implement a
forward method. Refer to reading [2] for a nice visual understanding of what
one of these layers looks like. The module is defined as:
class TransformerEncoderLayer(nn.Module):
def __init__(self, args):...
def upgrade_state_dict_named(self, state_dict, name):...
def forward(self, x, encoder_padding_mask, attn_mask: Optional[Tensor] = None):...
Notice the forward method, where encoder_padding_mask indicates the padding postions
of the input, and attn_mask indicates when computing output of position, it should not
consider the input of some position, this is used in the MultiheadAttention module.
There is a subtle difference in implementation from the original Vaswani implementation
to tensor2tensor implementation. In the former implmentation the LayerNorm is applied
after the MHA module, while the latter is used before. In this module, it provides a switch normalized_before in args to specify which mode to use.
TransformerDecoder
A TransformerDecoder has a few differences to encoder. First, it is a FairseqIncrementalDecoder,
which in turn is a FairseqDecoder.
Comparing to FairseqEncoder, FairseqDecoder
requires implementing two more functions outputlayer(features) and
getNormalizedProbs(net_output, log_probs, sample). Where the first method converts
the features from decoder to actual word, the second applies softmax functions to
those features.
FairseqIncrementalDecoder is a special type of decoder. During inference time,
a seq2seq decoder takes in an single output from the prevous timestep and generate
the output of current time step. In order for the decorder to perform more interesting
operations, it needs to cache long term states from earlier time steps. These includes
all hidden states, convolutional states etc. A FairseqIncrementalDecoder is defined as:
@with_incremental_state
class FairseqIncrementalDecoder(FairseqDecoder):
def __init__(self, dictionary):...
# Notice the incremental_state argument - used to pass in states
# from earlier timesteps
def forward(self, prev_output_tokens, encoder_out=None, incremental_state=None, **kwargs):...
# Similar to forward(), but only returns the features
def extract_features(self, prev_output_tokens, encoder_out=None, incremental_state=None, **kwargs):...
# reorder incremental state according to new order (see the reading [4] for an
# example how this method is used in beam search)
def reorder_incremental_state(self, incremental_state, new_order):...
def set_beam_size(self, beam_size):...
Notice this class has a decorator @with_incremental_state, which adds another
base class: FairseqIncrementalState. This class provides a get/set function for
the incremental states. These states were stored in a dictionary. Each class
has a uuid, and the states for this class is appended to it, sperated by a dot(.).
A nice reading for incremental state can be read here [4].
The TransformerDecoder defines the following methods:
class TransformerDecoder(FairseqIncrementalDecoder):
# Similar to TransformerEncoder::__init__
def __init__(self, args, dictionary, embed_tokens, no_encoder_attn=False):...
# Wraps over extract_features()
def forward(...):...
# Applies feed forward functions to encoder output. See below discussion
def extract_features(
prev_output_tokens,
encoder_out,
incremental_state,
full_context_alignment,
alignment_layer,
alignment_heads,
):...
# Convert from feature size to vocab size.
def output_layer(self, features):...
def max_positions(self):...
# Retrieves if mask for future tokens is buffered in the class
def buffered_future_mask(self, tensor):...
def upgrade_state_dict_named(self, state_dict, name):...
extract_features applies feed forward methods to encoder output, following some
other features mentioned in [5]. In particular:
- The decoder may use the average of the attention head as the attention output.
- The argument may specify
alignment_headsto only average over this many heads. This is anauto regressive maskfeature introduced in the paper.
TransformerDecoderLayer
A TransformerDecoderLayer defines a sublayer used in a TransformerDecoder.
In accordance with TransformerDecoder, this module needs to handle the incremental
state introduced in the decoder step. It sets the incremental state to the MultiheadAttention
module. Different from the TransformerEncoderLayer, this module has a new attention
sublayer called encoder-decoder-attention layer. This feature is also implemented inside
the MultiheadAttention module. See [4] for a visual strucuture for a decoder layer.
A TransformerDecoderLayer is defined as:
class TransformerDecoderLayer(nn.Module):
# setup components required for forward
def __init__(
self, args, no_encoder_attn=False, add_bias_kv=False, add_zero_attn=False
):...
# Requres when running the model on onnx backend.
def prepare_for_onnx_export_(self):...
def forward(
self,
x,
encoder_out,
encoder_padding_mask,
incremental_state,
prev_self_attn_state,
prev_attn_state,
self_attn_mask,
self_attn_padding_mask,
need_attn,
need_head_weights,
):...
Comparing to TransformerEncoderLayer, the decoder layer takes more arugments.
Since a decoder layer has two attention layers as compared to only 1 in an encoder
layer. The prev_self_attn_state and prev_attn_state argument specifies those
states from a previous timestep. The need_attn and need_head_weights arguments
are there to specify whether the internal weights from the two attention layers
should be returned, and whether the weights from each head should be returned
independently.
Among the TransformerEncoderLayer and the TransformerDecoderLayer, the most
important component is the MultiheadAttention sublayer. Let’s take a look at
how this layer is designed.
MultiheadAttention
Note: according to Myle Ott, a replacement plan for this module is on the way. My assumption is they may separately implement the MHA used in a Encoder to that used in a Decoder.
The methods implemented in this class:
@with_incremental_state
class MultiheadAttention(nn.Module):
def __init__(...):...
# Applies Xavier parameter initialization
def reset_parameters(self):...
# See discussion below
def forward(
self,
query,
key,
value,
key_padding_mask,
incremental_state,
need_weights,
static_kv,
attn_mask,
before_softmax,
need_head_weights,
) -> Tuple[Tensor, Optional[Tensor]]:...
# concatnate key_padding_mask from current time step to previous
# time step. Required for incremental decoding.
@staticmethod
def _append_prev_key_padding_mask() -> Optional[Tensor]:...
# reorder incremental state according to new_order vector
# Not used??
def reorder_incremental_state():...
# _input_buffer includes states from a previous time step.
# saved to 'attn_state' in its incremental state
def _get_input_buffer() -> Dict[str, Optional[Tensor]]:...
def _set_input_buffer():...
# Empty hook for internal use
def apply_sparse_mask(attn_weights, tgt_len: int, src_len: int, bsz: int):...
def upgrade_state_dict_named(self, state_dict, name):...
The forward method defines the feed forward operations applied for a multi head
attention sublayer. Notice that query is the input, and key, value are optional
arguments if user wants to specify those matrices, (for example, in an encoder-decoder
attention sublayer). In regular self-attention sublayer, they are initialized with a
simple linear layer. key_padding_mask specifies the keys which are pads.
There is an option to switch between Fairseq implementation of the attention layer to that of Pytorch.
Miscellaneous
LayerNorm is a module that wraps over the backends of Layer Norm [7] implementation.
It dynamically detremines whether the runtime uses apex
or not to return the suitable implementation.
PositionalEmbedding is a module that wraps over two different implementations of
adding time information to the input embeddings. They are SinusoidalPositionalEmbedding
and LearnedPositionalEmbedding. See [6] section 3.5.
References and Readings
- Extending Fairseq: https://fairseq.readthedocs.io/en/latest/overview.html
- Visual understanding of Transformer model. http://jalammar.github.io/illustrated-transformer/
- Reducing Transformer Depth on Demand with Structured Dropout https://arxiv.org/abs/1909.11556
- Reading on incremental decoding: http://www.telesens.co/2019/04/21/understanding-incremental-decoding-in-fairseq/#Incremental_Decoding_during_Inference
- Jointly Learning to Align and Translate with Transformer Models: https://arxiv.org/abs/1909.02074
- Attention is all You Need: https://arxiv.org/abs/1706.03762
- Layer Norm: https://arxiv.org/abs/1607.06450